数据湖架构(Data Lake Architecture):高效存储与处理海量原始数据的创新解决方案
分类:杂谈
日期:
数据湖架构(Data Lake Architecture)在现代软件开发及数据分析中占据了重要的地位。它不仅提供了一个灵活和可扩展的数据存储解决方案,同时也是支持大规模数据分析和查询的有效框架。本文将详细探讨数据湖架构的基本概念及其关键组件,并通过一个典型的实例进行说明。
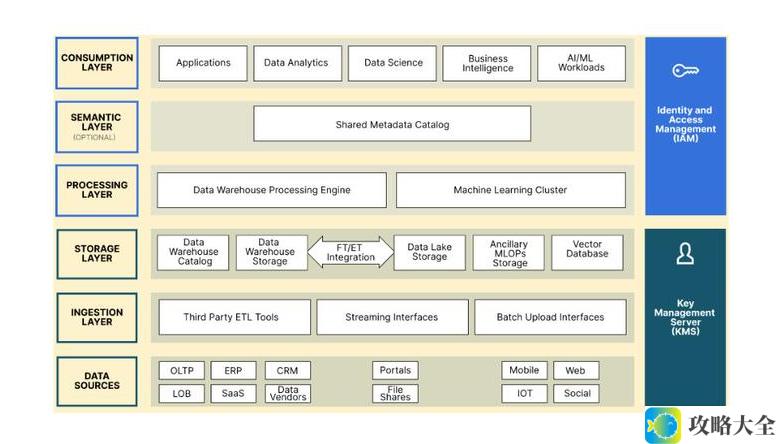
一、数据湖架构的基本概念
数据湖架构设计的基本理念是将各种类型和格式的数据以原始形式存储在一个集中系统中,而不需要事先定义数据结构或模式。这种方法使企业能够根据需要灵活地处理和分析数据,以满足数据驱动的现代业务需求。
二、数据湖架构的关键组件
- 存储系统:
- 数据湖通常采用分布式文件系统(如Hadoop HDFS、Amazon S3等)或对象存储(如Azure Blob Storage、Google Cloud Storage等)作为存储基础设施,以确保数据的可靠性和安全性。
- 数据采集和摄取:
- 架构内包含机制,用于从数据库、日志文件、传感器等多种数据源捕获数据,并导入数据湖。这通常采用ETL工具或流处理技术实现。
- 数据目录和元数据管理:
- 数据湖需维护一个数据目录,记录各数据集的元数据信息,这有助于数据发现和使用,提升可访问性和可管理性。
- 数据质量和数据治理:
- 数据治理策略的制定确保数据的准确性和完整性,同时保护数据隐私和合规性。
- 数据访问和查询:
- 提供灵活的数据访问方式,如SQL查询和编程接口,用户可根据需要选择检索和分析数据的方式。
- 分析和处理引擎:
- 架构支持各种分析引擎(如Apache Spark、Apache Flink等),可高效处理大规模数据,支持多种计算功能。
三、数据湖架构的优势
- 灵活性和可扩展性:
- 数据湖架构支持多种类型数据的存储,无需预定义模式,可与数据量的增长相适应。
- 低成本:
- 相比于传统数据存储方案,使用分布式系统和云存储能有效降低处理大量原始数据的成本。
- 高性能:
- 通过分布式计算和并行处理技术,数据湖架构可高效处理大规模数据,实现快速分析和查询。
四、实例讲解
以一家电商公司为例,该公司希望构建数据湖架构来存储和分析业务数据。具体实施方案包括:
- 选择存储系统:
- 该公司选择Amazon S3作为存储系统,因其提供高可用性和支持多种数据格式。
- 数据采集和摄取:
- 利用ETL工具将数据从多个源捕获并导入Amazon S3,同时使用流处理技术实时接收传感器数据和用户行为数据。
- 数据目录和元数据管理:
- 建立数据目录记录各个数据集的元数据信息,使用工具提高数据的可发现性和可管理性。
- 数据质量和数据治理:
- 实施数据治理策略,保证数据的准确性和一致性,并通过监控工具解决数据质量问题。
- 数据访问和查询:
- 提供多种查询方式,让用户根据需要选择最合适的方式进行数据检索和分析。
- 分析和处理引擎:
- 使用Apache Spark等进行大数据处理,支持批处理和流处理等多种分析任务。
通过上述实例,可以看出数据湖架构为企业提供了灵活及高效的数据解决方案,支持大规模数据的处理与分析。
问题:
- 什么是数据湖架构的主要特点?
- 数据湖架构中的数据治理为什么重要?
- 如何利用数据湖架构提升数据分析的效率?